Building AI Agents
This summer, I had the opportunity to intern at QuinStreet Inc (NASDAQ: QNST), where I worked on a common challenge in customer service: creating a smarter, more helpful chatbot. As a statistician, building this system meant diving deep into software engineering principles: system design, performance handling, API integration, and working with existing production systems.
LLMs have many obvious benefits for customer support functions, as well as interesting emergent properties that make them uniquely well-suited to this task. I worked on all parts of building this chatbot, including the design of the ‘agent’ (prompt and context engineering, tool building) and making the system performant to keep users engaged (managing latency, tone, and evaluations).
System Architecture
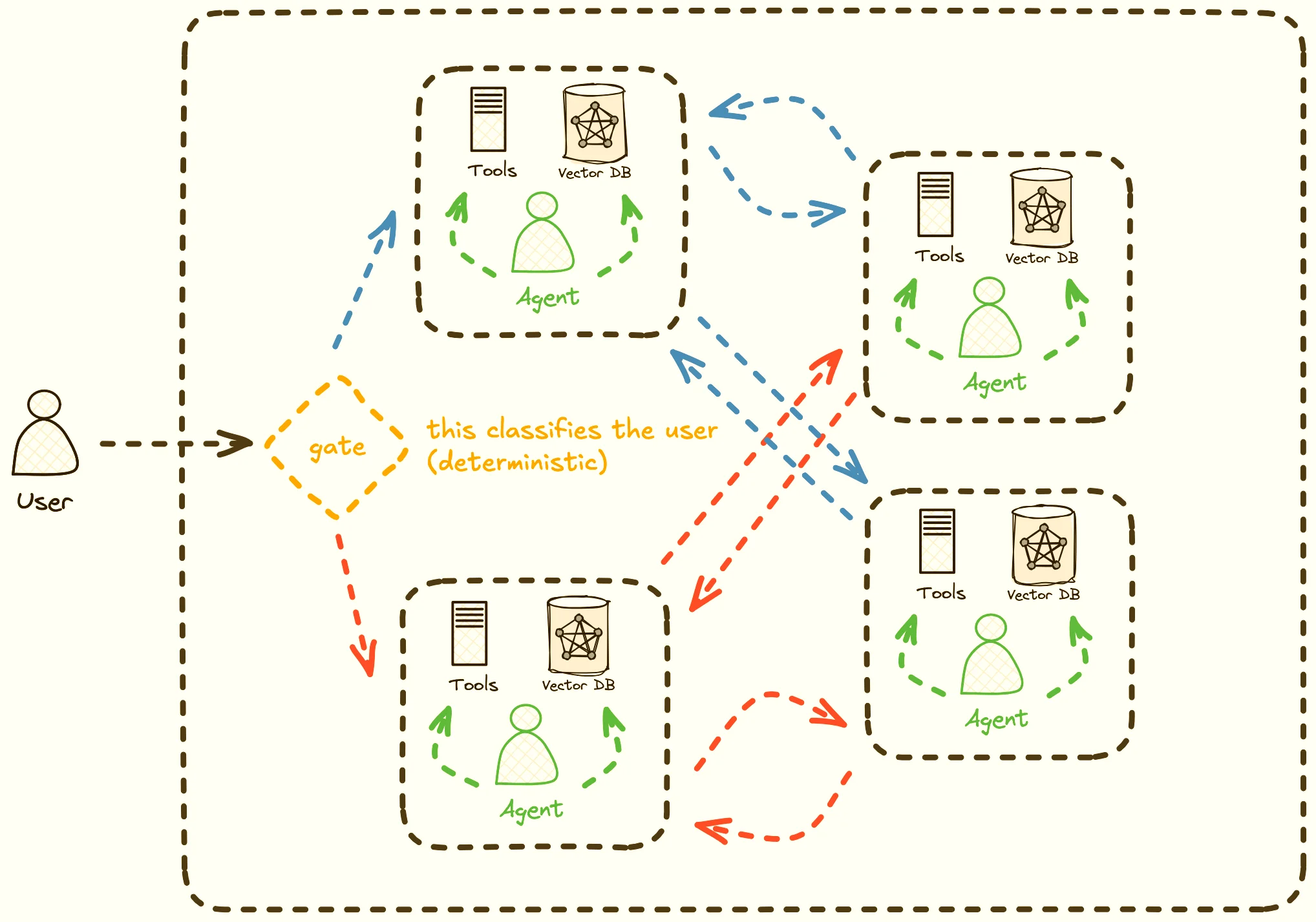 Figure 1: A (rough) diagram of our multi-agent system. Note that there is some initial segmentation done (i.e. of customers seeking loans vs insurance), but the agents also possess the ability to pass queries between each other.
Figure 1: A (rough) diagram of our multi-agent system. Note that there is some initial segmentation done (i.e. of customers seeking loans vs insurance), but the agents also possess the ability to pass queries between each other.
These multi-agent systems are useful for several key reasons:
- Efficiency: Each agent has a smaller, more specific system prompt, reducing latency and token expenditure (cost)
- Security: Each agent only has access to the information you decide to give it (so there’s no chance of accidentally offering loan terms to customers looking for insurance)
- Specifically, we have some tools that cost money to call (paid APIs), so we don’t want to call these unless necessary.
- Accuracy: In my testing, keeping an agent’s purpose specific rather than vague helped to reduce hallucinations.
Agent Handoffs
The handoff mechanism where an agent passes a query to another agent works very similarly to a tool call (see the OpenAI Agents SDK for an example). When a handoff happens in response to a user query, it’s as if the new agent took over the conversation.
Interesting Discoveries
Some properties I observed during this project:
Native Multilingual Support: LLMs are trained on vast corpora spanning many languages. We got tremendous value from this, since a large chunk of our user base is natively Spanish-speaking and the model would seamlessly switch to Spanish mid-conversation.
Information Architecture Tradeoffs: Giving your model external information involves careful tradeoffs. A vector database can store thousands of pages of insurance regulations, but querying it isn’t as reliable as pinging a purpose-built API via tool calls, which is itself slower and more expensive than simply appending information to the system prompt. We ended up using a mixture of all three methods.
Evaluation Complexity: Good evals are critically important. We tried using a prebuilt framework, but the results were inadequate, so I spent a week building custom evaluations for our use case.
Evolution and Results
The architecture changed significantly throughout development—I added more agents, moved some tools to be called at session start and cached rather than giving models the option to call them, and tested most frontier and open-source models.
The results were encouraging: we saw measurable increases in conversion rates in A/B tested traffic where the bot was live. Having a 24/7 multilingual assistant with infinite patience proved invaluable—many users had extended conversations about obscure information within the knowledge base.
Looking Forward
I’m bullish on the potential of these systems to take over many similar tasks. For customer support specifically, the combination of availability, patience, and deep knowledge access is compelling.
I look forward to channeling my inner Neo in the future and taming all the agents :)